What Can Nearly 2 Quadrillion Annualized Tokens Tell Us About LLM Pricing Trends?


Token pricing has become one of the biggest questions in AI as usage surges and model providers compete aggressively on cost. But what do real-world pricing trends actually look like? Drawing on nearly 2 quadrillion annualized tokens across enterprise and developer ecosystems, YipitData examines how effective LLM pricing has evolved in 2026, why headline API rates often miss the full picture, and what the data reveals about the diverging behaviors of enterprises and developers.
Over the past several months, token prices and reining in cost have become one of the most important themes in the AI ecosystem after material spend growth year-to-date.
The concern is understandable: Anthropic’s run-rate revenue reached $47bn in May vs. $9bn at the end of 2025, some companies are beginning to charge by the token rather than seat, and there are numerous model providers offering significantly cheaper tokens with similar levels of intelligence.
Some sources have recently claimed there is a shift happening. But when we examine usage-based data at scale, the reality appears far more nuanced.
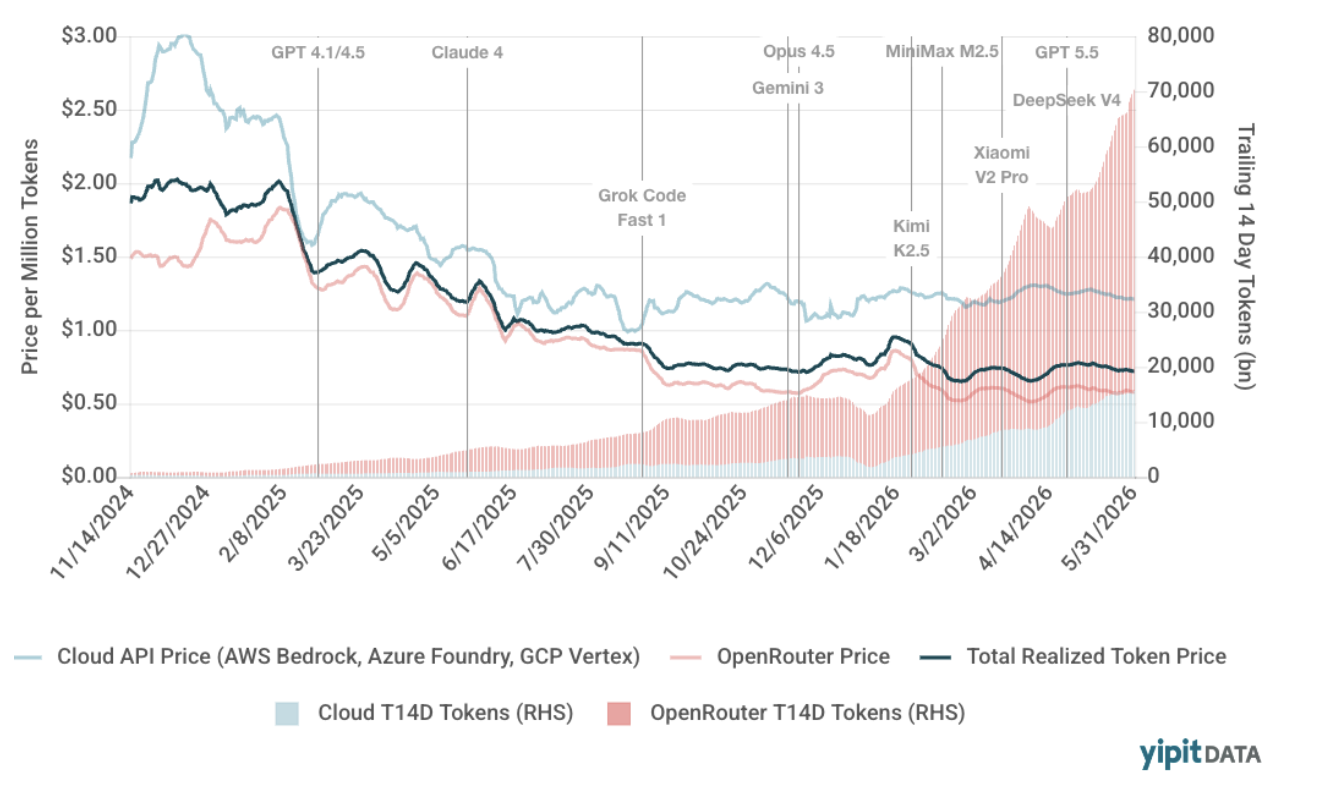
At YipitData, we now track a combined ~150 trillion monthly tokens across two distinct datasets representing nearly 2 quadrillion annualized tokens consumed. Through the end of May, our data shows that effective token pricing across API services has declined only 6% year-to-date. That’s also minimal compared to the sharp pricing compression seen in the second half of 2025.
Two Markets, Two Different Stories
Our data captures two very different segments of the AI ecosystem:
- Enterprise consumption, tracked through our Cloud product, which monitors enterprises accessing LLMs through cloud API services like Bedrock. This panel represents approximately $20 billion in annualized cloud spend, with many customers exceeding $100 million in annual cloud spend.
- Developer and startup consumption, observed through OpenRouter, a model routing platform serving more than 8 million global users.
Together, these datasets provide a broad view into how both enterprises and developers are adapting to the rapidly evolving LLM landscape.
Why Headline Pricing Often Misses the Real Story
Tracking token pricing accurately requires more than simply looking at posted API rates.
Effective pricing is importantly shaped by several factors:
- Input versus output token mix
- Prompt caching adoption
- Model selection behavior
- Context length (long context can often be 2x the cost of short context)
- Workload optimization patterns
Prompt caching, in particular, has become a major driver of effective pricing changes. By reusing previously processed prompts, organizations can reduce input token costs by roughly 90%, materially lowering blended pricing without any official API price cut.
Prompt Caching Intensity on OpenRouter:
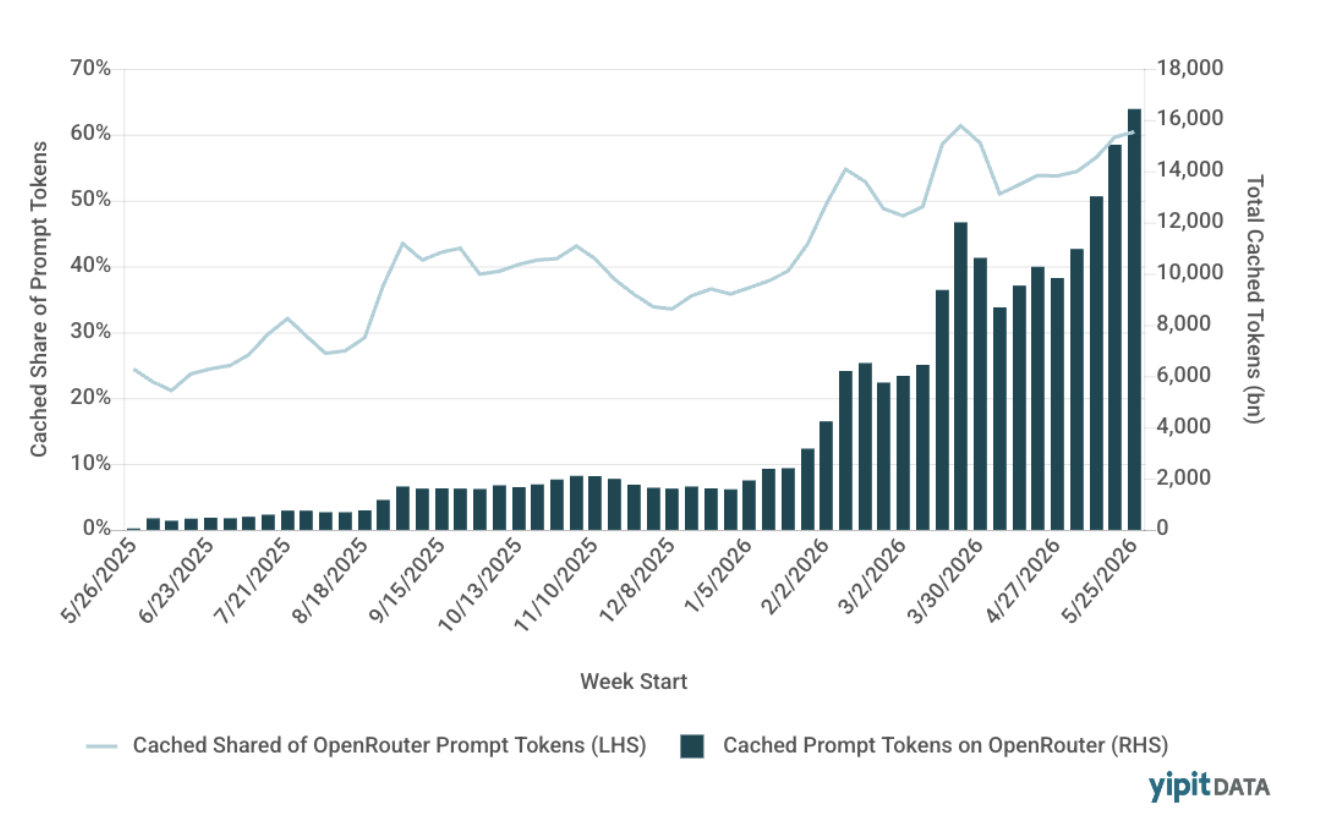
As a result, headline model pricing often tells only part of the story.
The Drivers Behind Recent Pricing Declines
Token prices have generally trended downward since late 2024, though not in a straight line.
Several factors have contributed to this decline:
- Increased adoption of prompt caching
- Direct model price reductions
- Greater usage of lower-cost, high-performance models
Notable pricing moves included:
- Anthropic’s 67% price reduction for Opus 4.5 in late 2025
- OpenAI’s 50% GPT-4o input token price cut in August 2024
- Rapid adoption of efficient models like Kimi K2.5 and, more recently, DeepSeek V4 Flash
However, the impact of these changes has varied significantly across customer segments.
Developers Are Optimizing Aggressively
On OpenRouter, where users are likely price-sensitive and frequently optimize for the best token-per-dollar outcome, we’ve observed far more rapid shifts toward lower-cost models.
By the end of March, blended token pricing on OpenRouter had fallen approximately 15% compared to the start of 2026, and usage is well-diversified across frontier providers and low-cost alternatives.
This reflects a market where users actively experiment with routing, switching providers, and leveraging emerging open-source or lower-cost alternatives as soon as they become viable.
Enterprises Still Prefer Frontier Models
Enterprise behavior has looked very different.
Despite broad model availability across services like Bedrock and Foundry, enterprise customers continue to show strong preference for premium frontier models.
In our enterprise cloud data, we have not observed meaningful changes in effective model pricing across providers since the start of the year, and customers are actually increasing their allocation of token volume to high-end models.
This suggests that, at least for now, reliability, performance, governance, and vendor trust remain more important than minimizing token costs for large-scale enterprise deployments.
The Bigger Picture
When combining both datasets, the result is a surprisingly modest 6% year-to-date decline in effective token pricing.
That stands in stark contrast to the second half of 2025, when token pricing fell 39% between July and year-end:
- OpenRouter experienced a 44% decline as providers like xAI and Z.ai took share
- Hyperscaler pricing declined approximately 20% when Google took share with Gemini 2.0 and 2.5
While lower-cost models and optimization techniques continue to gain traction, the data suggests the market is stabilizing, especially among enterprise buyers who remain willing to pay for leading model performance.
How YipitData Helps Clients Track AI Pricing Trends
AI infrastructure economics are evolving rapidly, and understanding real-world token pricing requires more than static API pricing tables.
YipitData helps clients monitor these trends through:
- Our Cloud product, which offers research reports alongside daily and weekly granular feeds containing everything from LLM spend by model to compute and storage spend.
- Our AI & Software package, featuring dedicated coverage of OpenAI and Anthropic
- Our B2B GenAI product, including an interactive dashboard to monitor AI tokens, pricing, and market share trends in real time
Connect with us!



.svg)

